
Bilder mit freundlicher Genehmigung der Forschungsteilnehmer*innen
Ist dir schon mal aufgefallen, wie unterschiedlich Suchergebnisse ausfallen? Deine Freunde und du könntet am selben Ort, zur selben Zeit genau dasselbe Wort googlen und ihr würdet mit sehr hoher Wahrscheinlichkeit trotzdem ganz unterschiedliche Suchergebnisse erhalten. Dass Suchergebnisse so unterschiedlich ausfallen, liegt daran, dass deine Suchergebnisse personalisiert, also genau auf dich und deine Interessen abgestimmt sind. Aber wer oder was bestimmt eigentlich was wir im Internet sehen?
Im Rahmen meines Forschungsprojektes untersuchte ich, wie erwachsene Suchmaschinennutzer*innen zwischen 20 und 30 Jahren mit Suchmaschinen und deren Personalisierung umgehen. Die Methode der Wahl war hierbei das leitfadengestützte Interview und die Anwendung von Visualisierungshilfen der Akteur-Netzwerk-Theorie (ANT) um die empirisch gewonnen Daten zu analysieren.
Doch beginnen wir zunächst mit den Wirkmechanismen von gängigen Suchmaschinen:
Wer zieht die Fäden im Hintergrund? Die unsichtbaren Anteile der Suchmaschine
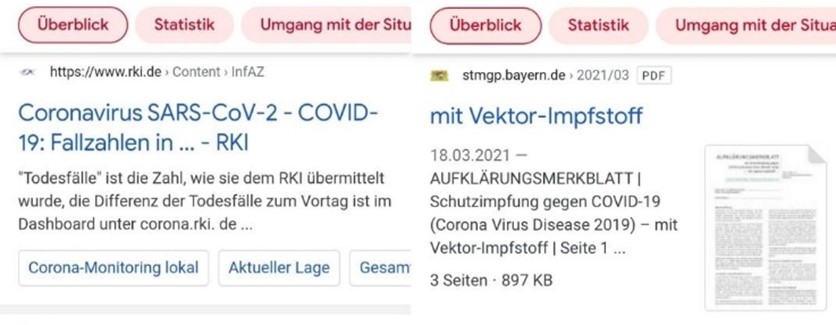
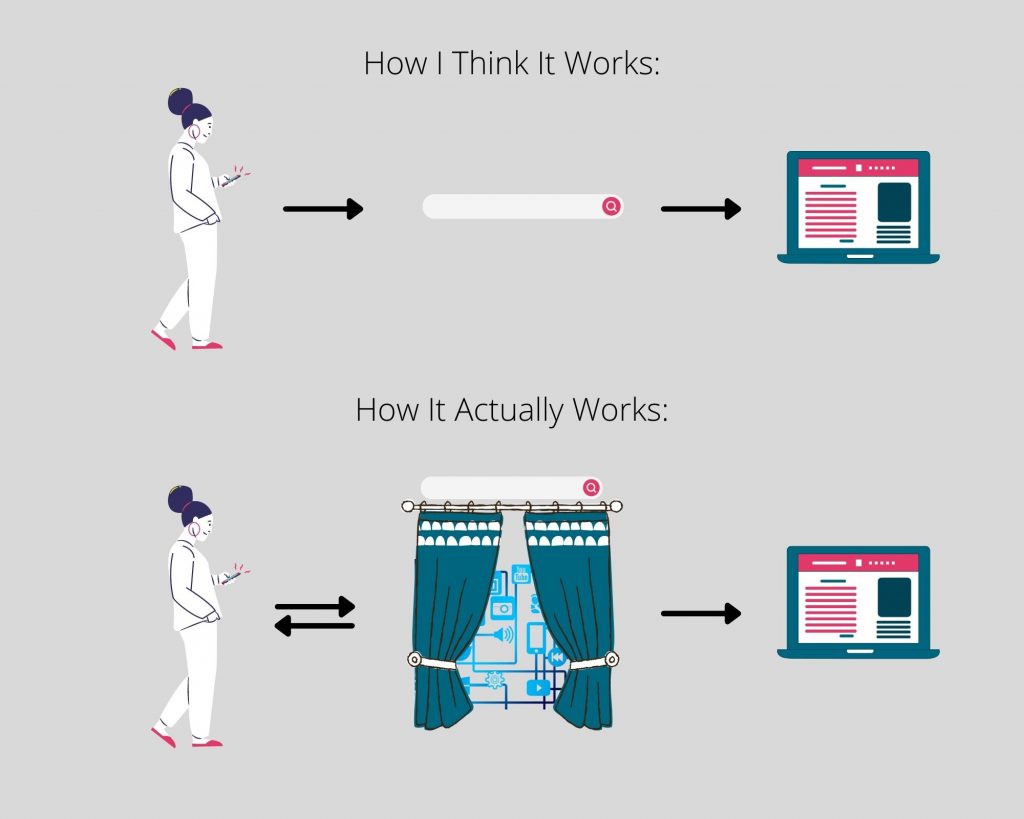
Bei der Betrachtung zweier Suchergebnisseiten wird die Unterschiedlichkeit von Suchergebnissen auf den ersten Blick sichtbar (vgl. Abb. 1). Die Google-Suche weist eine diverse Anzahl von Akteur*innen auf, bei der die Suchmaschinennutzer*innen (überraschenderweise) lediglich ein Knotenpunkt von vielen sind. Diese Perspektive verdeutlicht, dass man zunächst zwischen sichtbaren und unsichtbaren Komponenten von Suchmaschinen unterscheiden kann. Was wir bei der alltäglichen Nutzung der Google-Suchmaschine sehen, beschränkt sich auf die Benutzeroberfläche (Interface), unseren Suchbegriff und die anschließenden Ergebnis- oder Trefferseiten. Die Funktionsweisen von Google, also wie die Suchmaschine an unsere Trefferliste kommt, bleiben dabei unsichtbar und entziehen sich so unserer Wahrnehmung (vgl. Abb. 2). Hinter dem Interface der Suchmaschine arbeiten eine Reihe an Computerbefehlen, unter anderem Algorithmen, welche die Reihung unserer Suchergebnisse, und somit das, was wir als erstes sehen, maßgeblich mitgestalten.
Die unsichtbaren Prozesse der Suchmaschine umfassen das Erfassen und das Auffinden von Websites, die Erstellung eines Inhaltsregisters oder Index und die Bewertung der erfassten Websites. Wenn wir einen Suchbegriff eingeben, durchsucht die Suchmaschine demnach nicht das gesamte World Wide Web, sondern ausschließlich den Index nach Überschneidungen mit dem Suchbegriff und präsentiert uns speziell für uns sortierte Suchergebnisse. Diese Sortierung – auch Ranking genannt – geschieht durch Algorithmen, welche eine Reihe von Daten auswerten, die das Unternehmen der Suchmaschine über ihre Nutzer*innen sammelt. Hierbei werden unter anderem Geräteinformationen, Standortdaten, vorherige Suchen, Kaufaktivitäten, Personenkontakte und vieles mehr genutzt, um „Dienste zu verbessern“ und „relevantere Suchergebnisse“ (Google 2021) anzuzeigen. Welche Faktoren Googles aktueller Algorithmus berücksichtigt, und wie diese Daten im Detail genutzt und ausgewertet werden, ist als Betriebs- und Geschäftsgeheimnis klassifiziert.
(Grafik: Lina Harich)
Personalisierung: Nutzungsfreunlich oder Filterblase?
Personalisierung führt in der Praxis dazu, dass wir in der Regel schnell das passende Ergebnis für unsere Suche finden. Dennoch wird sie auch kritisiert. Rechtswissenschaftler und Politologe Eli Pariser zeigte etwa, dass die Personalisierung von Suchergebnissen zu einer Formierung von problematischen, informationshomogenen Filterblasen führen kann (vgl. Pariser 2011). Er argumentiert, dass die Personalisierung von Suchmaschinenergebnissen, beeinflusst durch detaillierte Persönlichkeits- und Nutzungsprofile, Nutzer*innen in Filterblasen isoliert. In diesen personalisierten Inhalten wird lediglich unsere eigene Meinung widergespiegelt und wir werden nicht mehr mit anderen Sichtweisen konfrontiert. Anstatt Alle mit Allen zu verknüpfen, isoliert das Internet seine Nutzer*innen auf diese Weise möglicherweise in eine Art Echo Chamber, was laut Pariser im schlimmsten Fall zu einer Gefahr für die demokratische Ordnung werden kann (vgl. Pariser 2011). Die konkrete Kritik an Content-Personalisierung umfasst vor allem, dass ausnahmslos jede*r Nutzer*in personalisierte Inhalte erhält, die genauen Wirkweisen der Datenauswertung und der Funktionsweisen für die Nutzer*innen jedoch unsichtbar bleiben und diese sich nicht für oder gegen Personalisierung entscheiden können (vgl. ebd.). Google wiederum bestreitet die Existenz von vorsätzlich algorithmisch geformten Filterblasen und gibt an, Personalisierung finde nicht oft statt und würde die Suchergebnisse nicht dramatisch verändern (vgl. GoogleWatchBlog).
In meiner Forschung interessiert mich besonders, ob personalisierte Suchergebnisse in Alltagspraktiken sichtbar werden und wie die Nutzer*innen von Google & Co. mit Personalisierungen oder Filterblasen umgehen und wie sie diese bewerten. Dabei sind Wissensbestände (wie auch die Ergebnisse meiner ethnografischen Forschung) „nie neutral“, sondern „geprägt von den Kontexten und Zeitumständen [und] in einer spezifischen Zeit und an einem spezifischen Ort situiert“ (Kuhn 2020:521). Der spezifische Kontext meiner Erhebung widmet sich deutschsprachigen Erwachsenen zwischen 20 und 30 Jahren, welche – beeinflusst durch ihr Aufwachsen mit einer Reihe an digitalen Medien – gewisse Wissensbestände und Technikkompetenzen für solche aufweisen. Eine Forschungsteilnehmerin bezeichnet beispielsweise die Nutzung von unterschiedlichen Persönlichkeitsprofilen zur Bereitstellung personalisierter Ergebnisse und Werbeanzeigen, als „Allgemeinwissen“ (Juliet: Studentin, 25, Suchmaschinennutzerin). Spannend ist dennoch, dass obwohl Wissensbestände um datengesättigte Nutzungsprofile und Content-Personalisierung bei den befragten Suchmaschinennutzer*innen vorhanden sind, nur selten eine kritische Haltung gegenüber Zwangspersonalisierung eingenommen wird.
Nutzungsfreundlichkeit wichtiger als Datenschutzbedenken?
Es zeigt sich, dass Nutzer*innen die Personalisierung von Suchergebnissen grundlegend positiv bewerten. Dennoch führt die dafür notwendige Sammlung personenbezogener Daten zu Bedenken über den Schutz der eigenen Daten. Auch in den genutzten Praktiken und der Suche nach Alternativen zu prominenten Suchmaschinen lässt sich dieses Abwiegen zwischen Datenschutzbedenken und Benutzer*innenfreundlichkeit aufzeigen. Obwohl die Nutzer*innen den Datenschutz der Google-Suchmaschinennutzung kritisch kommentieren, wird Google als benutzer*innenfreundlicher und qualitativ hochwertiger wahrgenommen als alternative Suchmaschinen und somit (fast) konkurrenzlos genutzt. Eine Forschungsteilnehmerin berichtet:
„Ich würde sagen zu über 90% [nutze ich] Google. Wenn überhaupt sind es meistens […] technische Probleme, die mich dazu bringen was anderes zu benutzen. Auf der Arbeit habe ich das manchmal, dann greife ich auf Bing zu, oder manchmal nutze ich auch DuckDuckGo. Habe ich eine ganze Zeit lang exklusiv gemacht, weil ich mal wegen der Daten mich informiert hatte und bin aber zu dem Ergebnis gekommen, […] dass man das zwar zur Alltagsrecherche gut nutzen kann, wenn man aber tiefergehend irgendwas recherchieren will, ist halt einfach die Suchergebnisauswahl mangelhaft. Kommt immer drauf an was man will. Um jetzt rauszufinden, was weiß ich, wie der letzte Freund von XY hieß, geht das, aber sobald man halt damit irgendwie tiefer einsteigen will, reichen die Ergebnisse nicht mehr aus.“
– Valerie: Journalistin, 24, Suchmaschinennutzerin
(Bild: © Statista 2021)
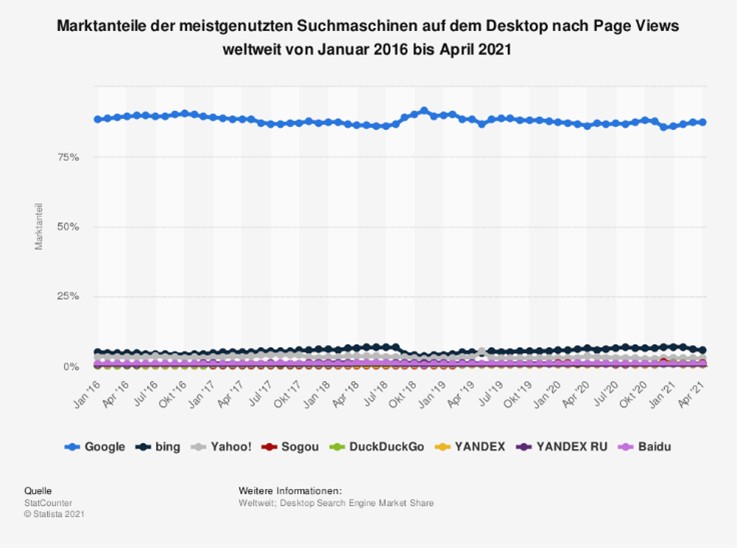
In den weltweiten Nutzungsstatistiken spiegelt sich ein ähnliches Bild. Im weltweiten Vergleich kommt Google auf einen Marktanteil von 87,29% bei der Desktop-Suche und auf rund 90% bei der mobilen Suche (vgl. Statista 2021) und hängt seine Konkurrent*innen somit um Längen ab (vgl. Abb. 3). Auch Publizist und Wissenschaftler Pascal Jürgens argumentiert mit seinen Mitautor*innen, dass die meisten Nutzer*innen die individuelle Anpassung der Suchergebnisse positiv bewerten, auch wenn die dafür erforderliche Sammlung persönlicher Daten kritisch gesehen wird (2014:107f.). Es lässt sich schlussfolgern, dass die Monopolstellung von Google dazu führt, dass die Suchmaschine als einzig passende Lösung für die eigene Lebenssituation wahrgenommen und Datenschutzbedenken für deren Nutzung in Kauf genommen werden.
„Und dann ist es manchmal super offensichtlich. Vorher war ich auf Pinterest unterwegs und habe mir Schuhe angeschaut und dann sind die Werbeanzeigen eher modebasiert.“
– Juliet: Studentin, 25, Suchmaschinennutzerin
Wahrgenommen wird die Personalisierung der Inhalte auf der Suchergebnisseite vor allem durch die bezahlten Werbeanzeigen, die in Google Suchergebnislisten auftauchen und visuell nur durch die Markierung als Anzeige von anderen Sucheinträgen unterscheidbar sind. Den Nutzer*innen ist bekannt, dass diese Werbeanzeigen als Teil des personalisierten Inhalts algorithmisch anhand von auf dem Gerät gespeicherten HTTP-Cookies ausgewählt werden. Dies regt bei einigen Nutzer*innen eine regelmäßige Leerung des eigenen Cache– und Cookie-Speichers an. Eine Forschungsteilnehmerin berichtet, dass sich die Personalisierung ihrer Suchergebnisse dadurch zeigt, dass ihre Suchergebnisse im Laufe der Suchmaschinenbenutzung immer konkreter werden, obwohl sie nach jeder Browsernutzung ihren Cache leert (Juliet, Studentin, 25, Suchmaschinennutzerin). Ihre Reaktion auf diese Personalisierung ist entschieden kritisch und führte zu detaillierter Auseinandersetzung mit Datenschutzrichtlinien und Cookie-Technologien. Die Grenze zwischen legitimer Marktforschung und dem Ausspionieren von Nutzer*innen ist für sie fließend.
Vertrauen als ausschlaggebender Faktor
Den genannten Datenschutzbedenken gegenüber steht die Bewertung von Google als qualitativ hochwertige Suchmaschine, welche ihre Qualität vor allem durch die gesammelten Personendaten aufrechterhält. An dieser Stelle zeigt sich ein weiteres zentrales Dilemma: Vertrauen. Während Juliet äußerst kritisch und auf ihre Daten bedacht die Google-Suche nutzt, äußert Valerie eine deutlich positivere Erfahrung mit der Nutzung von Google-Produkten. Sie berichtet:
„Und genauso wie man halt Google als Suchmaschine sehr vertraut, denke ich halt auch, dass man Google-Tochterunternehmen in dem Moment vertraut, weil die halt einfach diese massive Seitenmenge […] und die Datenmenge haben“.
– Valerie, Journalistin, 24, Suchmaschinennutzerin

(Grafik: Lina Harich)
Valerie führt die Benutzer*innenfreundlichkeit der Google-Suche also auf die immense Seiten- und Datenmenge zurück, auf welche Google für die Erstellung gerankter Suchergebnisse zugreift (ebd.). In diesem Zitat wird ebenfalls deutlich, dass die Forschungsteilnehmerin darauf vertraut, dass Google die gesammelten Seiten und Daten nicht zu ihrem Nachteil verwendet. Sie grenzt die Datenspeicherung durch Google von anderen Datensammlungen wie dem Phishing ab. Es wird darauf vertraut, dass Google die Datensammlungen – wie durch den Konzern angegeben – zur qualitativen Verbesserung der eigenen Dienste und zum Vorteil der Nutzer*innen verwendet. Die Monopolstellung Googles wirkt sich demnach eindeutig auf das entgegengebrachte Vertrauen aus. Ein selbiges Vertrauen findet sich auch in manchen wissenschaftlichen Meinungen. So argumentiert Mathematiker Carsten Hartmann, dass Suchmaschinenergebnisse nicht zwangsläufig in Filterblasen enden und diese durchaus einen wissensbasierten Konsens darstellen können. Er fasst zusammen, dass bei „Suchmaschinenergebnisse[n], die zuverlässig und beständig in eine bestimmte Richtung deuten, ein Konsens zwischen verschiedenen Wissenssubjekten zugrunde liegt, für den epistemisches Wissen unter bestimmten Voraussetzungen die beste Erklärung ist“ (Hartmann 2020:45).
Google als Eingangstor ins Internet
Suchmaschinen haben also nicht nur das Potenzial Filterblasen zu bilden, sondern ebenfalls epistemisches Wissen offenzulegen. Ob die personalisierten Suchergebnisse als hilfreich oder limitierend wahrgenommen werden, liegt also letztendlich im Auge der betrachtenden Person. Journalist*innen zufolge legt Google offen, dass die Personalisierung der Google-Suchergebnisse gering sei und in der Praxis wenig bis keinerlei Auswirkungen habe (vgl. Nebe 2019), und auch eine Studie der gemeinnützigen Nichtregierungsorganisation AlgorithWatch kommt zu ähnlichen Ergebnissen. Insgesamt wurden 3 Millionen gespendete Datensätze von fast 4.000 Nutzer*innen im Vorfeld der Bundestagswahl 2017 auf politischen Bias in den Suchergebnissen untersucht. Festgestellt wurde, dass es bis auf regionale Effekte angepasst an Gerätestandortdaten kaum Raum für Personalisierung gab und sich im Mittel von neun organischen Suchergebnissen sieben bis acht der Suchergebnisse nicht unterschieden (vgl. Krafft et al. 2017).
Klar ist aber, dass Google als meistgenutzte Suchmaschine weltweit für viele Menschen das Eingangstor ins Internet darstellt und somit einen enormen Einfluss darauf hat, welche Informationen für einen Löwenanteil der Weltbevölkerung im Internet sichtbar werden und welche Informationen unsichtbar bleiben. Diese durch die Google-Algorithmen sortierte Sichtbarkeit steht dennoch im offenkundigen Kontrast zur Intransparenz der Wirkmechanismen der Algorithmen, welche über die „Relevanz“ unserer Inhalte für uns entscheiden sollen. Auch wenn die Theorie der Filterblasen von verschiedenen Forscher*innen teilweise sehr unterschiedlich bewertet wird, illustrieren solche Untersuchungen die potenzielle Beeinflussung der Öffentlichkeit durch unsichtbare Quellcodes. Im Umgang mit digitalen Medien sollten wir uns dennoch fragen, aus welchen Gründen wir welchen Unternehmen vertrauen und wie wir in Zukunft mit möglichen Reibungspunkten von gefürchteten Datenschutzbedenken und erwünschter Nutzungsfreundlichkeit umgehen wollen.
Alle Beiträge des Lehrforschungsprojekts Beyond the Black Mirror
Lina Harich
… ist Masterstudentin der Transkulturellen Studien/Kulturanthropologie an der Rheinischen Friedrich-Wilhelms-Universität Bonn. Im Bachelor studierte sie englische Sprach- und Kulturwissenschaft, sowie Deutsch als Zweit- und Fremdsprache an der Universität Bonn. Ihre Forschungsinteressen umfassen Geschlechterforschung, Populär- und Subkulturen, kulturelles Erbe und die Auswirkungen von sozialen Konstrukten, wie Geschlecht und Sprache, auf die Wahrnehmung der gesellschaftlichen Wirklichkeit. Suchmaschinen faszinieren sie, da sie häufig als „objektiver“ wahrgenommen werden als sie sind und Digitalität breitflächig und dennoch kaum wahrnehmbar in unseren Alltag inkorporieren.
Quellen:
Alle Forschungsmaterialien wurden im Frühjahr 2021 erhoben. Die Daten wurden anonymisiert und liegen bei der Autorin.
- Google (2021): Datenschutzerklärung. Online hier (Zuletzt aufgerufen am 30.05.2021).
- GoogleWatchBlog (2018): Google-Nutzer in der Filterblase? Google weist die Aussagen der DuckDuckGo-Studie zurück. Online hier (Stand: 06.12.2018).
- Hartmann, Carsten (2020): Gefangen in der Filterblase? Suchmaschinenergebnisse als Beispiel eines wissensbasierten Konsenses. In: Peter Klimczak/Christer Petersen/Samuel Schilling (Hrsg.): Maschinen der Kommunikation. Interdisziplinäre Perspektiven auf Technik und Gesellschaft im digitalen Zeitalter. Wiesbaden, S. 45-62.
- Jürgens, Pascal/Stark, Birgit/Magin, Melanie (2014): Gefangen in der Filter Bubble? Search Engine Bias und Personalisierungsprozesse bei Suchmaschinen. In: Birgit Stark/Dieter Dörr/Stefan Aufenanger (Hrsg.): Die Googleisierung der Informationssuche. Berlin, S. 98-135.
- Krafft, Tobias et al. (2017): Filterblase geplatzt? Kaum Raum für Personalisierung bei Google-Suchen zur Bundestagswahl 2017. Online hier (Stand: 08.09.2017).
- Kuhn, Konrad J. (2020): Wissen. In: Timo Heimerdinger/Markus Tauschek (Hrsg.): Kulturtheoretisch argumentieren. Münster/New York, S. 520-550.
- Nebe, Tom (2019): So entgehen Sie der Bevormundung durch die Suchmaschine. Online hier (Stand: 30.07.2019).
- Pariser, Eli (2011): The Filter Bubble. How the New Personalized Web is Changing What We Read and How We Think. New York/London.
- Statista (2021): Marktanteile der meistgenutzten Suchmaschinen nach Page Views weltweit von Januar 2016 bis April 2021. Online hier (Stand: 19.05.2021).
0 Kommentare