
„Im praktischen Sinne haben wir eine KI, deren Fähigkeiten sowohl für unsere eigene Intuition als auch für die Erschaffer der Systeme unklar sind. Eine, die manchmal unsere Erwartungen übertrifft und uns zu anderen Zeiten mit Falschaussagen oder Erfundenem enttäuscht. Eine, die lernfähig ist, aber oft wichtige Informationen falsch erinnert. Kurz gesagt, wir haben eine KI, die sich sehr wie eine Person verhält, aber auf eine Art und Weise, die nicht ganz menschlich ist. Etwas, das bewusst erscheinen kann, es aber (soweit wir wissen) nicht ist. Wir haben eine Art fremden Verstand erfunden.“ (Ethan Mollick, übersetzt von Claude)
Im September 2023 veröffentlichten Marion Näser-Lather und Hanna Kanz auf diesem Blog einen Denkanstoß, in dem sie dazu aufriefen, die Nutzung generativer Künstlicher Intelligenz (GKI), also Anwendungen wie ChatGPT, in der Empirischen Kulturwissenschaft (EKW) zu reflektieren und zu diskutieren. Seitdem ist viel Zeit vergangen und GKI ist mittlerweile im akademischen Alltag angekommen und wird die akademische Landschaft nachhaltig verändern. Neben einer Vielzahl neuer Anwendungen hat sich auch die Literatur und disziplinäre Auseinandersetzung zu GKI erweitert. Auch gibt es seither immer mehr Forschungsprojekte, welche sich konkret mit GKI in den Geistes- und Sozialwissenschaften auseinandersetzen.
In unserem Projekt Hybrid Epistemic Practices an der Universität Tübingen etwa untersuchen wir ethnografisch die Transformation der Geistes-und Sozialwissenschaften durch GKI. Dieses Projekt zielt auf eine kritische ethnografische Bestandsaufnahme dessen, wie GKI in den Geistes- und Sozialwissenschaften eingesetzt und verhandelt wird. Im Rahmen dieses Projektes führten wir bereits eine universitätsweite Umfrage unter Studierenden und Mitarbeitenden durch, grundsätzlich nähern wir uns dem Feld jedoch durch ethnografische Interviews mit Mitarbeiter*innen und Fokusgruppen mit Studierenden. Zum aktuellen Zeitpunkt haben wir 15 Interviews und sechs Fokusgruppengespräche geführt.
Trotz des rasanten Einzugs in die Universitätslandschaft gibt es aber weiterhin viel Skepsis, Ratlosigkeit und zunehmend auch Diskussionen über gute wissenschaftliche Praxis im Kontext von GKI. Auch stellt sich vielen, wie Marion Näser-Lather und Hanna Kanz in ihrem Blogpost anmerkten, die Frage nach dem Selbstverständnis, vor allem in Fächern, die sich oft wesentlich über das Schreiben definieren. Was macht es mit einem Fach wie der Empirischen Kulturwissenschaft, wenn eine Maschine plötzlich per Knopfdruck überzeugende Texte schreiben oder plausible Interpretationen unseres Datenmaterials vorschlagen kann? Auch Studierende zweifeln mitunter am Nutzen ihres Studiums oder an der Sinnhaftigkeit bestimmter Prüfungs- und Lehrformate. Diese Konflikte beschäftigen derzeit viele Disziplinen und werfen grundsätzliche Überlegungen zur zukünftigen Rolle des Menschen in der Wissenschaft auf.
Andere, eher pragmatische Fragen zielen darauf, welche Anwendungen und Nutzungsweisen wirklich produktiv sind und an welchen Regeln und Prinzipien wir uns in unserer Nutzung orientieren sollen. Wie schaffen wir es, sinnvolle Workflows im Umgang mit GKI zu entwickeln, die unsere Arbeit wirklich verbessern und nicht, wie es oft in der Nutzung mit GKI der Fall ist, verschlimmbessern? In diesem Blogbeitrag möchte ich in Bezug auf eine aktuelle Lehrveranstaltung, eigene Erfahrung und unser aktuelles Forschungsprojekt über derlei Fragen reflektieren und dabei drei Prinzipien vorschlagen, welche uns zu einem sinnvollen und produktiven Umgang mit GKI verhelfen können. Dabei beziehe ich mich insbesondere auf die Situation kleiner Fächer, wie eben der EKW, und gehe an verschiedenen Stellen auf konkrete GKI-Anwendungen ein, welche häufig im Universitätskontext verwendet werden. Zunächst aber möchte ich einen kurzen Überblick über die Nutzung und über mögliche Einsatzmöglichkeiten von GKI geben.
Nicht-nutzung ist eine bewusste Entscheidung
Was sich in unseren Daten in jedem Fall beobachten lässt, ist, dass sich kaum mehr Studierende und Mitarbeitende finden lassen, die noch gänzlich auf die Nutzung von GKI verzichten. So konnten wir durch unsere universitätsweite Umfrage im April 2024 feststellen, dass etwa die Hälfte aller Studierenden und Mitarbeitenden der Universität Tübingen GKI bereits regelmäßig (mindestens einmal pro Woche) in ihrem Studien- und Forschungsalltag einsetzen (und dabei gibt es keinen signifikanten Unterschied zwischen den Geistes- und Sozialwissenschaften einerseits und den Naturwissenschaften andererseits) (Grießl, Bareither, und Vepřek, 2024).
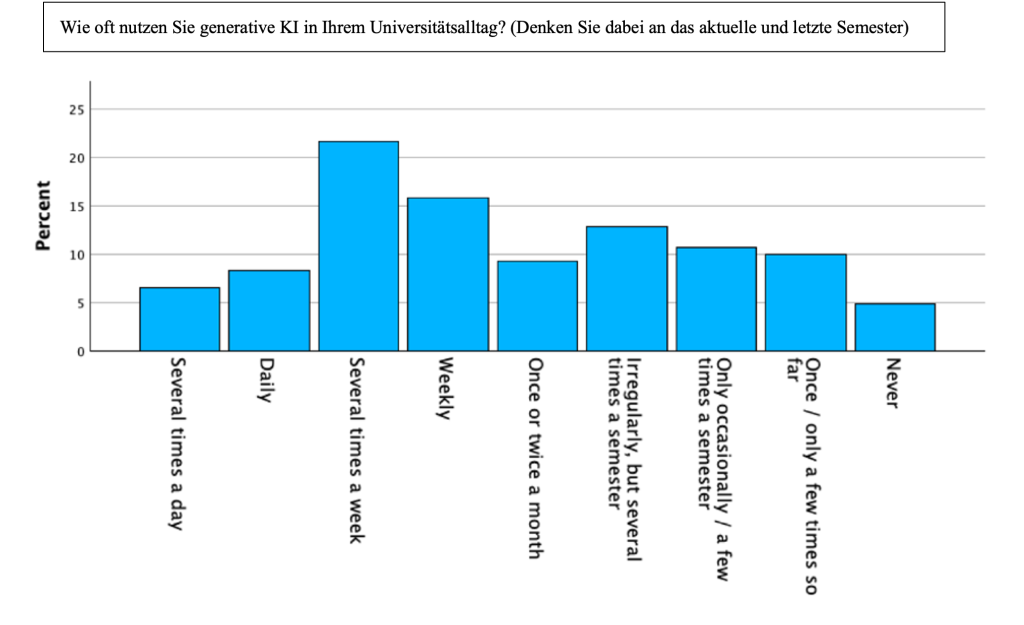
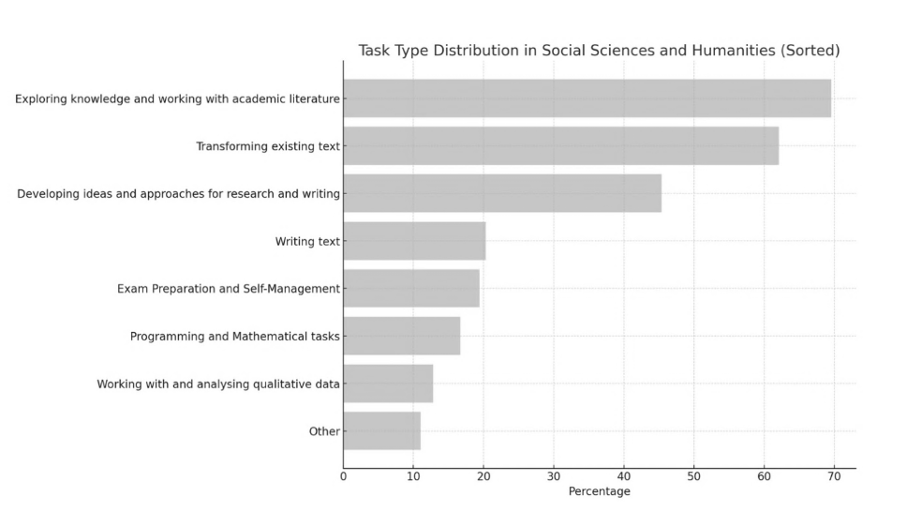
Andere Umfragen aus dem gleichen Erhebungszeitraum, wie etwa Hahn (2024) kommen auf ähnliche Zahlen. Interessant ist hierbei auch, dass bestimmte Aufgabenbereiche besonders häufig mit GKI bearbeitet werden: So wird GKI von Studierenden wie Mitarbeitenden vor allem zum Arbeiten mit akademischer Literatur, dem Wissenserwerb, zur Erklärung fachlicher Konzepte, zur Übersetzung eigener Texte sowie zur Verbesserung von Stil und Grammatik verwendet. Die tatsächliche Generierung von Text oder das Erstellen ganzer Hausarbeiten o.ä. scheint, so zeigen es zumindest die Umfragedaten, kein allzu stark verbreitetes Phänomen zu sein, welches bei Mitarbeitenden zudem deutlich häufiger vorkommt als bei Studierenden. Dabei hat sich insbesondere die Kategorie des „Transformierens“ von bereits bestehendem Text – etwa durch Übersetzung oder stilistische Glättung – als besonders weit verbreitet herausgestellt.
In Bezug auf das Vertrauen, welches Studierende und Forschende GKI gegenüber haben, ließ sich zeigen, dass eine grundsätzlich neutrale und ambivalente Haltung vorherrscht, mit dem Trend, dass das Vertrauen mit zunehmender Nutzungshäufigkeit steigt, aber mit ansteigendem akademischen Status sinkt. Auch konnten wir feststellen, dass das Vertrauen steigt, je mehr Vorwissen Nutzer*innen über GKI haben.
Insgesamt zeigt sich, dass GKI inzwischen in vielen Bereichen des universitären Alltags ganz selbstverständlich verwendet wird – eine Beobachtung, die sich auch deutlich in den Interviews und Fokusgruppen widerspiegelt. Studierende und Mitarbeitende berichten dort immer wieder von konkreten Nutzungsszenarien, in denen GKI bereits fest zur Praxis gehört, vom Druck, GKI einsetzen zu müssen, und dem Gefühl, andernfalls abgehängt zu werden.
„[A]m Anfang wollte ich es so wenig wie möglich einsetzen, weil ich auch dachte, ich muss das doch alles selber machen, da hatte ich diese Angst sehr, weil ich halt gesehen habe, dass es alle um mich rum nutzen und dadurch viel schneller sind als ich. […] Gleichzeitig habe ich mich auch ein bisschen, hatte ich ein bisschen schlechtes Gewissen, weil ich dachte, jetzt lerne ich es halt nicht mehr richtig. Aber ich habe schon diesen Druck verspürt, aufzuspringen auf den Zug, weil ich sonst zurückbleibe. Und weil ich sonst Nachteile gegenüber den anderen habe, die das ja alle vermeintlich nutzen.“ (Promotionsstudent*in)
Es ist offensichtlich, dass GKI für viele längst im Universitätsalltag verankert ist. GKI nicht oder nur für ausgewählte Anwendungen zu verwenden, ist heute meist eine ganz bewusste Entscheidung.
„Aber KI ist bei allen angekommen, merke ich immer wieder. Also […] im Seminar sitzen sie auch teilweise davor und, und, also es ist viel direkter da, als ich das erwartet hatte [..].“ (Postdoktorand*in)
Einsatzmöglichkeiten von GKI in der Empirischen Kulturwissenschaft
Grundsätzlich lässt sich beobachten, dass GKI für eine ganze Reihe von Aufgaben eingesetzt wird. Eine dieser Aufgaben ist die Unterstützung bei der Literaturrecherche. Neben dem Klassiker ChatGPT gibt es Anwendungen wie Research Rabbit, Elicit oder ScienceOS, welche spezifisch für die Wissenschaft und die Literaturrecherche zugeschnitten sind. Die Nutzung dieser Tools zeigt jedoch oft, dass sie nicht auf kleine Fächer angepasst sind und einen daher oftmals in Richtungen lenken, die wenig zielführend sind. So kommt es häufig vor, dass Texte aus völlig anderen Fachkulturen vorgeschlagen werden oder dass Theorien und Ansätze der EKW gar nicht berücksichtigt werden. Besonders hilfreich ist GKI in diesem Bereich dann, wenn bereits eine klare Vorstellung davon besteht, was gesucht wird – etwa die deutsche Übersetzung eines Papers oder der Name einer Autorin, der einem gerade entfallen ist. In solchen Fällen kann GKI wertvolle Unterstützung bieten, auch wenn das Risiko von Halluzinationen (erfundene oder fehlerhafte Inhalte, die überzeugend dargestellt werden) weiterhin besteht. GKI kann klassische Literaturrecherche ergänzen, aber nicht ersetzen.
Neben der Nutzung zur Literaturrecherche kann GKI auch für die inhaltliche Erschließung eines Forschungsfelds eingesetzt werden. Sie ermöglicht es, Ideen und Anregungen zu erhalten, eigene Gedanken zu hinterfragen, neue Impulse zu bekommen und Konzepte weiterzuentwickeln. Auch kann sie Vorschläge für Forschungsfragen und theoretische Perspektiven liefern oder blinde Flecken im eigenen Denken aufzeigen. Ein weiteres wichtiges Anwendungsfeld in diesem Kontext ist die Interaktion mit wissenschaftlichen Texten, da GKI hochgeladene Dokumente oder ganze Textkorpora zusammenfassen, erklären und analysieren kann. Besonders in Kombination mit einer intensiven Auseinandersetzung mit Texten kann sie dabei wertvolle Impulse liefern.
Neben der inhaltlichen Arbeit mit Texten wird GKI auch häufig zur sprachlichen Verbesserung genutzt. Sie kann helfen, Grammatik und Stil zu optimieren, einen bestimmten Jargon nachzuahmen oder sprachliche Glättungen vorzunehmen. Insbesondere für Nicht-Muttersprachler*innen oder Personen mit Rechtschreibschwächen kann dies hilfreich sein. Eng damit verbunden ist die Nutzung von KI für Übersetzungen. Auch wenn sie nach aktuellem Stand nicht an professionelle menschliche Übersetzungen heranreicht, kann sie das Textverständnis erheblich erleichtern. Die Kombination der Lektüre im Original mit einer KI-gestützten Übersetzung erweist sich so etwa als ein Modus, der es einem ermöglicht, einen Lerneffekt zu erzielen.
Eine derzeit stark diskutierte Anwendung ist der Einsatz in der qualitativen Datenanalyse. GKI kann dabei helfen, ethnografische und historische Daten zu sichten, zu sortieren und zu analysieren – etwa durch automatische Codierung, Zusammenfassungen oder Interpretationsvorschläge. Diese Funktionen können neue Perspektiven anregen, ersetzen aber nicht die eigenständige Analyse. Ein weiteres relevantes – und weniger umkämpftes – Anwendungsfeld ist die KI-gestützte Transkription von Audiointerviews. Diese funktioniert zwar noch nicht komplett fehlerfrei, ermöglicht es aber dennoch viel Zeit zu sparen, die dann wiederum für andere Aufgaben verwendet werden kann. Besonders in qualitativen Fächern ist dies eine durchaus wesentliche Veränderung, da sie einen ganz zentralen und zeitaufwändigen Arbeitsprozess stark verkürzt.
Während GKI, wie wir in dieser überblickshaften Darstellung gesehen haben, bereits in vielen Bereichen des akademischen Arbeitens Einzug gehalten hat, stellt sich insbesondere für kleinere Fächer die Frage, wie sich diese Technologie sinnvoll in bestehende Forschungs- und Lernprozesse integrieren lässt. Obwohl GKI-Tools vielfältige Unterstützung bieten können, sind sie meist nicht darauf ausgelegt, die spezifischen Perspektiven und Konventionen kleiner Fächer abzubilden. Vielmehr erfordert ihr Einsatz ein bewusstes und strategisches Vorgehen, um die eigenen Forschungs- und Lerninteressen gezielt zu unterstützen. Wie also kann GKI in kleinen Fächern produktiv genutzt werden?
Um mich dem etwas zu nähern, gab ich im Wintersemester 2024/25 ein Seminar zum Thema Generative Künstliche Intelligenz als Werkzeug und Gegenstand der Empirischen Kulturwissenschaft, welches als Experimentierraum diente, GKI auszuprobieren, einzusetzen und zu diskutieren. Das Seminar war so konzipiert, dass wir sowohl aktuelle Literatur zu GKI lasen und diskutierten als auch verschiedene Anwendungen erkundeten, um gemeinsam zu überlegen, wie sich diese in den jeweiligen Studien- und Forschungskontexten einbetten lassen. Angelehnt an KI-Experte Ethan Mollick‘s erste (von vier) Regeln für den Umgang mit GKI – „always invite AI to the table“ – wurden KI-Tools in diesem Seminar für jegliche Aspekte, etwa zur Moderation einer ersten Vorstellungsrunde, der Besprechung der Lektüre, zur Erstellung von Referatsfolien und Notizen, zur Interpretation von Datenmaterial oder als gut informierter Gesprächspartner eingebunden. So konnten wir bereits gemeinsam erproben und kollektiv imaginieren, wie GKI unsere Arbeit verändern wird, welche dieser Veränderungen wünschenswert sind und welche nicht, und wie wir uns dem Phänomen theoretisch nähern können.
Aufgrund der Erfahrung aus diesem Seminar und unserem Forschungsprojekt, schlage ich im Folgenden drei Prinzipien vor, die dabei helfen sollen, GKI sinnvoll und produktiv für kleine Fächer einzusetzen.
Generative KI für kleine Fächer nutzbar machen: Drei Prinzipien
Das erste Prinzip im Umgang mit GKI: Gib ihr Kontext, bevor du Antworten erwartest
Viele Vertreter*innen kleiner Fächer, wie der EKW, sehen sich oft mit dem Problem konfrontiert, dass deren Perspektiven, aber auch relevante Literatur, zentrale Konzepte oder Autor*innen im Datenmaterial der KI-Anwendungen nicht vorkommen. Dadurch entsteht das grundlegende Problem, dass generative KI-Modelle nicht nur bestehende Fachperspektiven verzerren oder ausblenden, sondern auch Wissenslücken reproduzieren oder schaffen können.
„Also […] ich habe Literaturrecherchetools [ausprobiert] […], aber da ist also für uns jetzt das Problem, für die Geschichtswissenschaft, dass es halt nur über diese Papers funktioniert und die gibt es bei uns auch, aber wir haben halt auch Monographien und die findet der schlecht und das ist, ne, also ich habe, ich habe dann meine eigene Forschung eingegeben und habe eine Rezension zu meinem Buch gefunden, von der ich noch nichts wusste, aber mein Buch hat er nicht gefunden.“ (Akademische*r Rat/Rätin)
So ist etwa bei ChatGPT gar nicht klar, auf welcher Datenbasis die Ausgaben beruhen. Eine überzeugend klingende Antwort kann also eine Mischung aus tatsächlich relevanten Texten, Wikipedia und Reddit Kommentaren sein. Das liegt unter anderem daran, dass das Internet eine schier unendliche Menge an Texten enthält, in denen sich nahezu jede erdenkliche Meinung, Position oder Interpretation findet. GKI-Modelle sind hervorragend darin, sprachlich flüssige und überzeugende Texte zu generieren, bieten jedoch keine Garantie dafür, dass sie eine Fachkultur repräsentieren oder Fakten korrekt wiedergeben. Aber auch genuin wissenschaftliche Chatbots wie ScienceOS erweisen sich für kleine Fächer teilweise als problematisch: ScienceOS etwa bezieht sich in seinen Ausgaben neben OpenAI‘s Sprachmodell auch auf den Semantic Scholar Index, welcher zwar viele Millionen Quellen umfasst, dabei die Publikationspraxis kleiner Fächer oftmals nicht wirklich berücksichtigt. In manchen Fächern spielt zum Beispiel die Publikation in Tagungsbänden eine zentrale Rolle, welche in journalzentrierten Datenbanken oft einfach nicht erfasst sind. Auch Elicit oder Consensus haben ihre Grundlage in der Semantic Scholar Datenbank, wodurch sich ähnliche Probleme ergeben. Um GKI gezielt für unsere Zwecke einzusetzen, müssen wir sowohl ihre Funktionsweise als auch die besonderen Anforderungen und Perspektiven unseres Fachs genau kennen. In der ein oder anderen Weise ist es also wichtig, der KI erstmal etwas beizubringen, bevor man von ihr lernen kann.
Ein möglicher Weg, generativer KI etwas beizubringen, ist es, ihr etwas an die Hand zu geben, womit sie arbeiten kann. Frage ich etwa ScienceOS nach der Bedeutung des Kürzels EKW, bekomme ich etwa die nicht zufriedenstellende Antwort, dass es sich dabei um den Einheitskostenwert handelt. Dies ist an sich natürlich verständlich, handelt es sich dabei womöglich um eine häufiger verwendete und deshalb wahrscheinlicher gesuchte Beschreibung als Empirische Kulturwissenschaft.
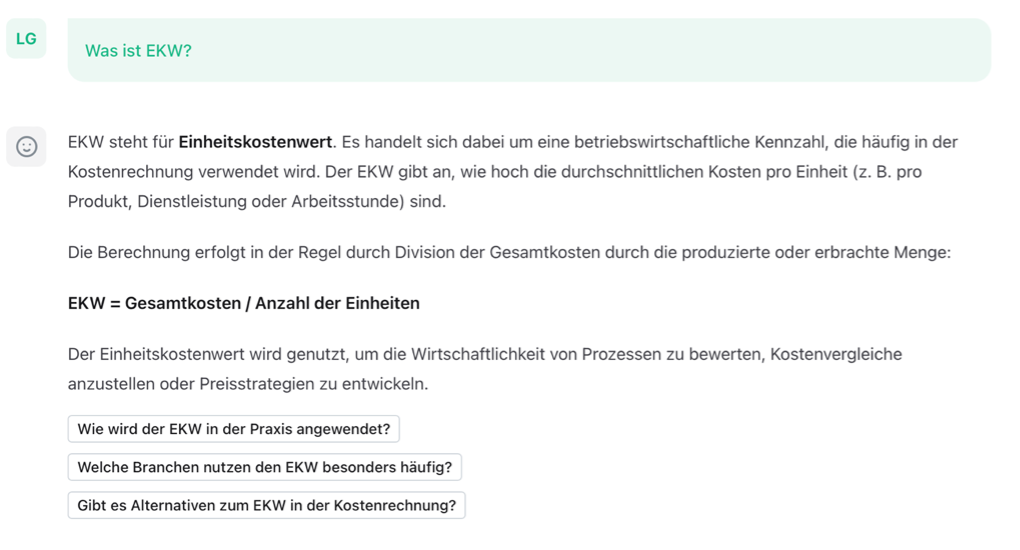
Füttere ich das gleiche KI-Tool allerdings mit relevanten Informationen, in diesem Fall 30 Publikationen aus der Empirischen Kulturwissenschaft, bekomme ich eine Antwort, die schon viel eher dem entspricht, was ich erwarten würde. Genau für diese Möglichkeit, mit einer eigenständig kuratierten Textauswahl zu interagieren, hat ScienceOS eine Bibliothek implementiert, welche von Nutzer*innen mit bis zu 4.000 PDFs gefüttert werden kann, die dann als Datenbasis für eine Anfrage dienen. Auf diese Weise lässt sich dem Problem, das GKI-Tools das eigene Fach nicht kennen und es daher auch nicht miteinbeziehen können, etwas entgegensetzen. Über diesen Weg lässt sich GKI so „erziehen“, dass sie durch die Lektüre gängiger Texte ein stückweit die Systematik und Eigenart eines Faches kennenlernt. In diesem Fall handelt es sich um Literatur aus einer Einführungsvorlesung und um Texte, welche die Studierenden als grundlegend für ihr Verständnis von EKW verstanden.

Eine andere Herangehensweise besteht darin, den GKI-Tools eine bestimmte Art zu „Denken“ explizit beizubringen. Ein Beispiel dafür ist etwa die Möglichkeit, ein sogenanntes CustomGPT zu trainieren, wodurch ein bestimmtes Hintergrundwissen oder eine Perspektive vorgegeben und der KI beigebracht wird. Für ein entsprechendes Experiment haben Studierende eine Reihe an Grundannahmen und Beschreibungen der EKW zusammengetragen, womit wir dann ein „EKW-GPT“ trainiert haben. Dieser EKW-GPT ist also so aufgebaut, dass es sich in der Generierung der Antworten an bestimmten Grundannahmen und Konzepten der EKW orientiert. Eine Alternative zu einem CustomGPT, das nur in der Bezahlversion von ChatGPT verfügbar ist, besteht darin, einen eigenen sogenannten Prompt zu formulieren, der diese Grundannahmen enthält. Ein Prompt ist dabei die Eingabe, die man der KI gibt, um eine bestimmte Antwort oder ein gewünschtes Verhalten zu steuern. Er kann aus einer einfachen Frage bestehen oder aus einer komplexen Anweisung, die der KI bestimmte Rahmenbedingungen oder eine spezifische Perspektive vorgibt. Dieser kann entweder bei jeder Anfrage neu eingegeben oder in einem fortlaufenden Chat gespeichert werden, auf den man immer wieder zurückgreift.

Eine dritte Möglichkeit, eine KI für die eigenen Zwecke anzupassen ist es, ihr eine Rolle zuzuweisen und ihr explizit den Auftrag zu geben, sich wie eine konkrete menschliche Rolle zu verhalten. So reicht oft ein einfacher Prompt, in welchem klar gemacht wird, was man selbst gerade möchte (z.B. Ideen für einen Seminarplan finden) und welche Rolle die KI dabei einnehmen soll (z.B. Herausgeberin einer Zeitschrift zu sein oder gerade dieses und jenes Buch gelesen zu haben). Diese Rollenzuschreibung strukturiert den weiteren Verlauf des Chats und ermöglicht es so, passendere Antworten zu bekommen. Diese gezielte Anpassung von KI-Tools kann nicht nur zu präziseren Antworten, sondern auch zu einer stärkeren Orientierung an den Eigenheiten kleiner Fächer führen. Aber auch hier kommen wir an das Problem, dass es zwar durch Rollenverteilung besser möglich wird, gezieltere und passendere Antworten zu bekommen, wir uns aber weiterhin nur auf das interne Wissen der Sprachmodelle beziehen können. Den Tools zusätzliches Material an die Hand zu geben, ist daher meistens der vorzuziehende Weg.
Es wird in der Praxis natürlich klar, dass die Antworten nicht perfekt sind, egal ob die Chatbots vortrainiert wurden oder nicht. Es wird aber auch klar, dass zusätzlicher Kontext einen wichtigen Unterschied macht und man so in der Lage ist, GKI für konkrete Zwecke besser zu nutzen. Je mehr Kontext ich der GKI in Bezug auf meine Anfrage gebe, desto besser ist sie auch in der Lage, mich bei meinem aktuellen Vorhaben zu unterstützen. Gebe ich ChatGPT das bisher geschriebene als Kontext, vervollständigt es diesen Absatz wie folgt: Letztlich geht es darum, die Interaktion mit KI als einen Prozess des wechselseitigen Lernens zu verstehen: Je präziser wir die KI in unsere Denkweise einführen, desto besser kann sie darauf reagieren. Diese Anpassung mag aufwendig erscheinen, doch sie eröffnet gerade für kleine Fächer die Möglichkeit, KI gezielt als Werkzeug einzusetzen, anstatt sich von ihren inhärenten Grenzen ausbremsen zu lassen.
Das zweite Prinzip im Umgang mit GKI: Nutze KI nur, wenn du Fach und Thema bereits verstehst
Verstehen als Voraussetzung
Das erste Prinzip, der KI erstmal etwas beizubringen und KI-Nutzung als wechselseitiges Lernen zu verstehen, setzt natürlich voraus, dass Nutzer*innen bereits einen bestimmten Wissensstand in Bezug auf Fach und Thema haben. Dies erweist sich als grundlegend, da es GKI-Tools, wie wir mittlerweile alle gelernt haben, mit der Wahrheit oft nicht so ganz genau nehmen. Michael Hicks, James Humphries und Joe Slater von der Universität Glasgow haben ChatGPT in Anlehnung an Harry Frankfurt eine Bullshit Maschine genannt, da das Tool lediglich auf Basis von Wahrscheinlichkeiten Antworten formuliert und deren Faktizität bzw. ihren Wahrheitsgehalt nicht überprüfen kann. Das Problem ist laut den Autoren der Studie nicht, dass GKI-Tools manchmal halluzinieren, sondern dass sie grundsätzlich nicht dafür gedacht sind, Fakten zu vermitteln. Sind die Ausgaben oftmals faktisch sogar korrekt, sind das also eher Zufallstreffer. Wahre und falsche Aussagen, so scheint es, haben für generative KI den gleichen epistemischen Wert. Es ist also wichtig, immer selbstständig in der Lage zu sein, darüber urteilen zu können, ob die Antworten generativer KI stimmig, sinnvoll und brauchbar sind, da KI-Modelle selbst nicht wissen können, ob das, was sie sagen, auch richtig und nützlich ist.
Das Wissen über die Funktionsweise generativer KI und damit einhergehend eine grundsätzlich skeptische Haltung ist etwas, das sich durchgehend unter Studierenden und Mitarbeitenden wiederfinden lässt, auch bei denen, die GKI täglich einsetzen. Dass diese Tools im Grunde nur „labern“, wie es eine Studentin in einer Fokusgruppe ausgedrückt hat, ist den meisten Anwender*innen im Universitätskontext klar, und dennoch wissen sie, dass ihre Ergebnisse oftmals wirklich nützlich und anschlussfähig sind. Sie werden das aber nur, wenn Nutzer*innen gelernt haben, die Antworten zu überprüfen – eine Beobachtung, die wir in unserer Forschung sehr häufig gemacht haben. Viele Wissenschaftler*innen und Studierende gaben etwa an, nur dann auf GKI zurückzugreifen, wenn sie diese Aufgaben auch eigenständig durchführen könnten bzw. in der Lage sind, die Ergebnisse auch zu prüfen. Dies gilt natürlich nicht für das Abfragen von Wissen oder Erklärungen, sondern auch für andere Anwendungen, etwa für Übersetzungen. Eine wirklich sinnvolle Nutzung von Übersetzungstools gibt es nur dann, wenn Benutzer*innen beide Sprachen bereits beherrschen, da sie nur dann in der Lage sind, die Ausgaben zu überprüfen und produktiv damit zu arbeiten.
Verstehen als Absicherung
Die Notwendigkeit des Verstehens lässt sich dabei noch auf eine andere Weise lesen. Während das Verständnis über Fach und Thema eine Voraussetzung darstellt, dient Verstehen zudem als Absicherung und besonders in qualitativ-orientierten Fächern, als epistemischer Kern. Bei GKI-Tools handelt es sich um Werkzeuge, die wir (unterstützend) einsetzen können. Qualitative Analyse und Interpretation werden vorerst nicht per Knopfdruck abschließend erledigt sein. Es bleibt also zentral, in der Nutzung von GKI der Human in the Loop zu bleiben, was auch einer von Mollick’s Regeln im Umgang mit GKI entspricht. Egal wie leistungsfähig KI-Tools werden, sie können, von Diskussionen über Artificial General Intelligence (AGI) einmal abgesehen, kein echtes Verstehen, keine eigene Verortung in der Welt und kein reflektiertes Bewusstsein für Bedeutung, Kontext oder die Implikationen ihrer Erkenntnisse entwickeln. Aber genauso wie GKI nicht weiß, welche Perspektiven sie übersehen hat, so kann sie gleichzeitig als Korrektiv für uns selbst und die Perspektiven eingesetzt werden, die wir in unserer Arbeit möglicherweise übersehen haben.
Auch wenn GKI-Anwendungen weiterhin den Hype Cycle bestimmen und sich mit neuen Modellen und Tools auch immer neue Versprechungen verbinden, bleiben diese Tools Stochastische Papageien, welche sprachliche Muster aus ihren Trainingsdaten nachahmen, aber kein tatsächliches Verständnis besitzen. Ihre Antworten klingen zwar oft überzeugend, sind aber nicht immer korrekt oder originell. Dennoch bieten sie wertvolle Unterstützung in vielen Bereichen, solange ihre Grenzen erkannt und kritisch reflektiert werden. Das Prinzip, dass Verstehen, sowohl im Sinne des fachlichen und thematischen Verstehens wie auch im Sinne eines Weber’schen Verstehens, hochgehalten werden muss, kann damit einen verantwortungsbewussten und produktiven Umgang mit GKI fördern.
Das dritte Prinzip im Umgang mit GKI: Entwickle eigene Workflows
Die meisten GKI-Tools sind als sogenannte Chatbots, also Plauderrobotter konzipiert, mit denen man sich über so ziemlich alles, von Geschäftsplänen über Liebeskummer bis zu ganz spezifischen akademischen Themen austauschen kann. Auch sind viele Anwendungen in der Lage, Dinge zu tun, von denen selbst regelmäßige Nutzer*innen noch gar nicht wussten, dass sie dazu fähig sind. So können manche Anwendungen etwa das Internet durchsuchen, .pptx oder iCal Dateien erstellen, Kommentare in Word Dokumenten hinterlassen, Bilder und Diagramme generieren oder Informationen aus einem Excel Sheet extrahieren. Es gibt dabei keine Bedienungsanleitung, sondern die Nutzung entwickelt sich durch Ausprobieren, durch Trial-and-Error. Damit unterscheiden sich die meisten GKI-Anwendungen durchaus stark von anderer Software, deren Nutzung man gezielt lernen und sich durch Handbücher oder Tutorials aneignen kann. Gleichwohl gibt es aber natürlich auch Tipps und Tricks, etwa wie man gut prompten kann. Doch dabei stellt sich immer die Frage, wer diese Empfehlungen formuliert, auf welchen Annahmen sie beruhen und für welche Zielgruppe sie gedacht sind. Schließlich sind solche Strategien nicht immer neutral, sondern spiegeln spezifische Vorstellungen von effizienter Interaktion mit KI wider. So kann man ChatGPT laut einer Studie etwa Trinkgeld anbieten, was angeblich oftmals zu ausführlicheren und strukturierteren Antworten führt.
Dabei ist zu beachten, dass während manche Nutzungsweisen möglicherweise für eine Person gut funktionieren, diese sich nicht zwangsläufig genauso gut an die Praktiken und Arbeitsweisen anderer Personen anschließen lassen. Zentral ist es also, individuelle Nutzungsweisen und Workflows zu entwickeln, welche an den individuellen Arbeitsalltag anknüpfen. Dabei konnten wir in unseren Interviews und Fokusgruppen beobachten, dass viele Nutzer*innen GKI so verwenden, dass sie ganz konkret auf die aktuelle Situation, die Umstände, Bedarfe oder Lerntypen der jeweiligen Personen angepasst sind. Auch wenn erfolgreiche Strategien nicht immer einfach von einer Person auf eine andere übertragbar sind, sondern erst durch eigenes Experimentieren und Anpassen ihre volle Wirksamkeit entfalten, so sollte der Austausch und Dialog über jeweilige Nutzungsweisen unter Kolleg*innen dennoch nicht zu kurz kommen, da sich so natürlich viele Möglichkeiten offenbaren, die wiederum in individuelle Workflows integriert werden können.
Im Rahmen einer Fokusgruppe berichtete etwa eine Studentin von einer Podcast-affinen Freundin: „Weil die eine Freundin hat mir erzählt, die hört immer Podcasts und lernt dann, also die ist voll krass, die weiß so viele Sachen und lernt ganz viel über Podcast. Und jetzt hat sie sich alles, also ihre Folien hat sie sich jetzt zusammenfassen lassen von KI und dann […] in ein Podcastskript übersetzen […] und das dann in so einer Text to Audio App übersetzen lassen. Und jetzt hört sie sich quasi ihre Zusammenfassung als Podcast an.“ (Studentin, EKW). Was sich hier also beobachten lässt ist die Entstehung einer ganz neuen Beziehung zwischen Präsentationsfolien und Audioformaten, welche bisher getrennte Lernmethoden waren. Dadurch wird eine neue Form des Lernens hervorgebracht, die sich, zumindest für diese Person, als besonders fruchtbar erweist.
GKI zum Untersuchungsgegenstand machen
Während diese Tools im Grunde nur scheinklug sind, zeigt sich in der Nutzung, dass sie uns in vielen Bereichen unterstützen können – allerdings nur, wenn wir sie als Werkzeuge begreifen, die wir aktiv gestalten und kritisch hinterfragen müssen. Gerade hier sollte die Empirische Kulturwissenschaft, wie es Professor Thomas Thiemeyer in einem Interview mit uns formuliert hat, „ihre macht- und technikkritischen Perspektiven auch darauf anwenden“. Denn GKI als „Alltagstechnik und Teil des Alltags zu verstehen, heißt natürlich, sich dem auch mit unseren Methoden zu nähern und umgekehrt wahrscheinlich auch unsere Methoden, die mit diesen Techniken jetzt möglich werden, zu erweitern“.
Diese Erweiterung unserer Methoden erfordert jedoch nicht nur technische Anpassungen, sondern auch eine kritische Reflexion darüber, welche epistemischen, methodischen und ethischen Implikationen mit der Nutzung von GKI einhergehen. Welche Wissensordnungen werden durch diese Technologien reproduziert oder verschoben? Welche blinden Flecken haben die Modelle, und wie können wir ihnen begegnen? Und welche neuen Möglichkeiten – aber auch Abhängigkeiten – entstehen durch den Einsatz dieser Werkzeuge? Diese Fragen sind nicht nur für kleine Fächer von Bedeutung, sondern berühren grundsätzliche Überlegungen zum Verhältnis von Mensch, Technik und Wissen. Indem wir GKI nicht nur nutzen, sondern sie auch als Untersuchungsgegenstand begreifen, können wir aktiv mitgestalten, wie sie unseren Forschungs-, Lehr- und Studienalltag prägt. Diese Reflexion ist für alle, besonders aber auch für kleine Fächer grundlegend.
Literatur:
Bender, Emily M., Timnit Gebru, Angelina McMillan-Major und Shmargaret Shmitchell. 2021. „On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?“ In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21), 3.–10. März 2021, virtuelles Event, Kanada, 14 Seiten. New York: ACM. https://doi.org/10.1145/3442188.3445922.
Frankfurt, Harry G. 2014. Bullshit. Übersetzt von Michael Bischoff. Berlin: Suhrkamp.
Grießl, Lukas, Christoph Bareither, und Libuše Hannah Vepřek. 2024. „Generative AI in Academia: A Survey of Students and Staff at the University of Tübingen“. Universität Tübingen. https://doi.org/10.15496/PUBLIKATION-99805.
Hahn, Laura Marie. 2024. Künstliche Intelligenz in der Hochschullehre. Masterarbeit, Technische Universität Darmstadt. Eingereicht am 30. Oktober 2024.
Hicks, M. T., J. Humphries und J. Slater. 2024. „ChatGPT is Bullshit.“ Ethics and Information Technology 26 (38). https://doi.org/10.1007/s10676-024-09775-5.
Mollick, Ethan. 2024. Co-Intelligence: Living and Working with AI. New York: Portfolio.
Müller, Nina. 2024. „Auch ChatGPT mag Trinkgeld: So prompten Sie die KI richtig.“ CHIP, 10. März 2024. https://www.chip.de/news/Auch-ChatGPT-mag-Trinkgeld-So-prompten-Sie-die-KI-richtig_185103352.html.
Abbildungsverzeichnis:
Abb. 1: Nutzung von GKI im universitären Alltag (Grießl, Bareither, und Vepřek, 2024: 9).
Abb. 2: Verteilung der Aufgabenbereiche in den Sozial- und Geisteswissenschaften (Grießl, Bareither, und Vepřek, 2024: 30).